任晓宁2024-07-17 15:11 
![]()

记者 任晓宁 “9.11和9.9谁大?”这个人类小学生都能正确回答的问题,难倒了一批大模型。7月17日上午,用这个问题询问了阿里巴巴的通义、腾讯的元宝、百度的文心一言、字节跳动的豆包,以及AI创业公司的大模型产品智谱清言、百小应、Kimi、海螺AI。8个大模型产品中,只有1个产品的回答正确。
回答错误的大模型产品,犯错的方式并不相似,它们背后的性格也各不相同。Kimi直截了当给出了几个字:“9.11大于9.9。”海螺AI的推理有一种荒谬感,它说,在比较整数部分时,因为9大于9,所以9.11比9.9大。
其余几个大模型产品都一本正经地分析这道题,并给出解题思路。它们的推理逻辑是正确的,但答案是错误的。它们都认为,应该先比较整数部分,当整数部分相同时,则比较小数点后第一位数。
通义倒在了推理的倒数第二步,它说,9.11的第一个小数位比9.9的第一个小数位大,因此9.11大。文心一言也是同样的逻辑,认为小数点后的第一位,1比9大。
豆包和百小应错在最后一步。它们说,因为1小于9,所以9.11大于9.9。
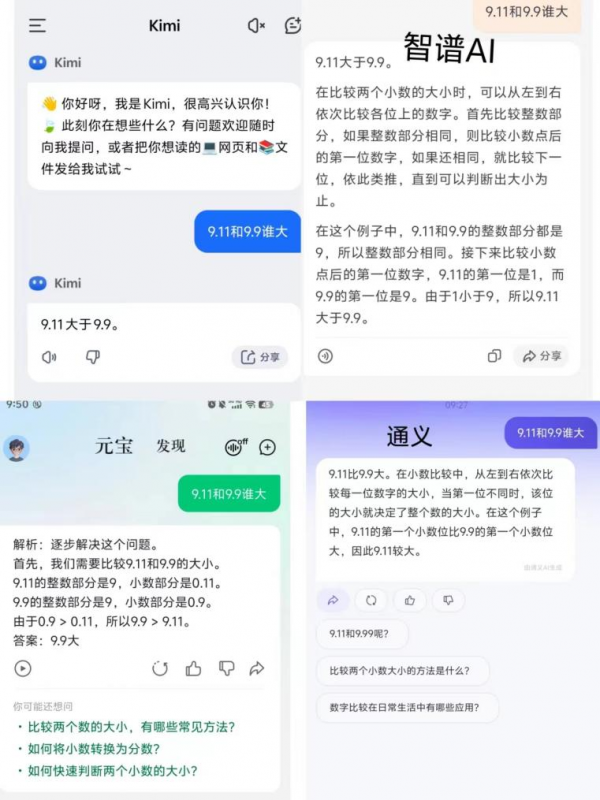 图1:大模型产品的回答
图1:大模型产品的回答
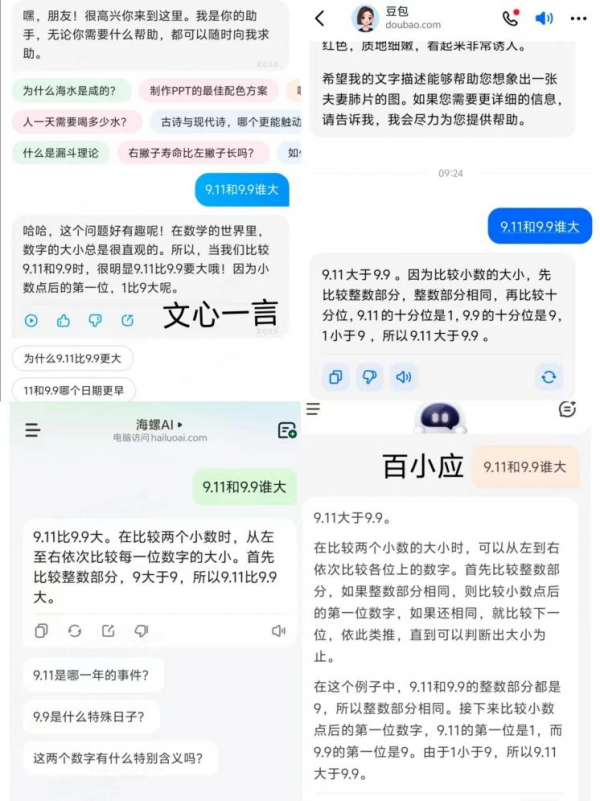
图2:大模型产品的回答
为什么号称能做奥数题的大模型,会犯这种低级错误?询问了几位大模型技术专家,他们的答案各不相同。
一位互联网大厂大模型技术人员说,上述错误是大模型数学推理能力不足的体现。从业内评估榜单上看,国内大模型和国外大模型在知识型问答上差距不大,但在更难一些的数学逻辑推理能力上相差明显。他认为,关键原因在于,大模型训练数据中,语言模型对浮点数(带有小数点的数字)的建模和理解是不到位的,因此导致了上述错误。
AI上市公司创新奇智首席技术官张发恩认为,上述错误与大模型的分词机制有关,在当前大模型技术链条上,分词组件(Tokenizer)是比较弱的一个环节,很多问题也是由此引发的。他举例说,比如9.11一般会被分为3个token(处理文本的最小单元):“9”和“.”和“11”。9.9也会被分为3个token:“9”和“.”和“9”。最后那个token的比较,容易让大模型搞错。
张发恩一直在训练工业大模型,见过大模型的各种错误。他认为,“9.11比9.9大”这种错误不算大事,人是高级智能体,可以做高级战略,但做三位数除法,口算一样容易出错,准确率不如计算器。
“随着大模型算法和工程技术进步,通过使用大模型的规划能力,或者智能调用专门的小工具,大模型这种错误会进一步减少。”张发恩说。

 京公网安备 11010802028547号
京公网安备 11010802028547号  购物车
购物车


 订阅
订阅



