2024-05-29 17:11

![]()

【经观讲堂】系经济观察报社年度培训项目,邀请来自经济、传媒、科学、文化、法律、商业等领域知名人士讲授常识与新知,分享经典和创新,是助力提升经观内容品质和传播影响的开放型课堂。
窦德景是北电数智首席科学家,复旦大学特聘教授,清华大学电子工程系兼职教授,此前曾担任波士顿咨询公司(BCG)合伙人、副总裁、中国区首席数据科学家,百度大数据实验室和商业智能实验室主任,美国俄勒冈大学计算机和信息科学系教授。他的研究领域包括人工智能、数据挖掘、数据整合、自然语言处理和健康信息学等。
本文根据窦德景在【经观讲堂】上的发言整理。
非常高兴能够来到《经济观察报》做这样一个分享,我把讲的内容分成两部分,一部分是前大模型时代,基本上是基于2022年之前的工作;一部分是大模型时代,也就是2022年之后发生的事情。在前大模型时代,大数据已经很火了,深度学习已经出来了,大模型也是深度学习技术发展的最新产物。当然我相信,除了大模型,以后还会有更强大、更先进的新的人工智能(AI)算法和模型出来。大模型就是现在最好的AI技术。
我给大家讲一点科普,也是给前大模型时代的AI正名。大模型出来了,前面的工作就没有意义了吗?不是这样的,其实前面的AI现在也还在用。而且很多时候,作为一家公司也好,作为一个政府组织也好,你可能没有那么多的成本直接上大模型。这些比较传统的、比较简单的AI,其实也可以用。
AI概念是如何出现的
那么我给AI先做一点简介。《人工智能:一种现代方法》(Artificial Intelligence: A Modern Approach)这本书,是斯图尔特·罗素(Stuart Russell)和彼得·诺维格(Peter Norvig)合写的,罗素是加州大学伯克利分校的教授,诺维格一直在谷歌工作。

《人工智能:一种现代方法》第三版和第四版的封面
大家一看就知道,这本书的封面是个国际象棋盘。如果你对AI的历史有了解的话,你会知道,这是因为1997年IBM的深蓝计算机在国际象棋上赢了加里·卡斯帕罗夫(Garry Kasparov)。这个封面是这本书的第三版,那时还没有第四版。2019年,我最后一次在俄勒冈大学教AI的时候,跟学生开玩笑,说你们可以预测一下第四版应该是什么样的封面。有的学生就猜到了,说第四版的封面应该是一个围棋盘。第四版在2020年出来了,封面其实也还是一个国际象棋盘,但是它把封面上的一位科学家换成了围棋盘。但我觉得第四版的封面应该对围棋大书特书,好好讲讲围棋对AI的贡献。
在AI的概念上,我一定要给AI正名。因为人工智能(Artificial Intelligence)这个英语单词的出现,是在1956年的达特茅斯会议上,由约翰·麦卡锡(John McCarthy)和马文·明斯基(Marvin Minsky)促成的。所以AI这个词是1956年出来的,它绝对比2022年出来的大模型要早得多,大家一定不要认为是因为有大模型才有AI的。
AI这个概念出现的时间,甚至比1956年还要早,因为1950年艾伦·图灵(Alan Turing)在图灵测试中就提出了这样一个概念,而且他用的词叫做机器智能(Machine Intelligence)。到底人工智能和机器智能哪个词更合适呢?我觉得都行。从技术角度来说,我觉得机器智能更合适,图灵希望机器拥有人的智能,但是从推广的角度来说,普通老百姓可能不太能够接受机器智能这个词,所以麦卡锡就创造了人工智能这个词。在英语里面,Artificial这个词既有人工的概念,又代表人造的东西。人工智能这个词,比图灵最早用的机器智能更受欢迎,所以后来大家都用人工智能了。
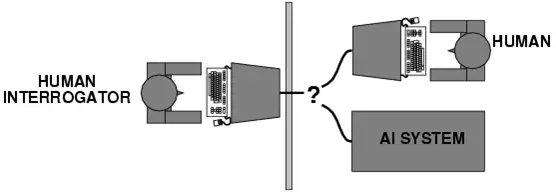
图灵测试示意图
为什么说图灵是AI的鼻祖?因为他在1950年就提出了这个概念,他觉得50年以后,机器在5分钟内有30%的可能性可以骗过人类。比如说做一个测试,图中左边是一位人类测试官,他来判断图中右边哪个是人、哪台是机器。其实在50年以后的2000年,我们基本上认为是没有机器能通过图灵测试的。但是从2000年开始,特别到了2010年深度学习出现以后,2022年大模型出来以后,我觉得AI的发展快了很多。现在我们基本认为,假如用比较原始的图灵测试的条件做测试的话,现在的GPT-4(美国AI公司OpenAI研发的大模型)应该就可以骗过人了。
因为各种各样的限制条件,最早图灵提出图灵测试的时候,通讯只是靠两根线连着。但是如果你想把中间的隔板去掉,造一台能够真的骗过人的机器,你得希望这台机器长得就像真人,这还是很困难的,我觉得可能还要再过几十年才能达到这个要求。但是图灵测试基本上比较早地就给大家指明了一个方向,我们要做一个AI,应该要做到什么样?GPT大模型可以产生文字、声音、视频,我觉得它已经比较完整了。但是你真要和它对话,聊久了,GPT也会露馅。因为当时图灵也说了,给5分钟的时间,看看机器能不能骗过人类。我觉得真要做这种测试,应该双盲的。它不能假定,像图中的图灵测试一样,隔板右边一定是一台机器和一个人。它不应该告诉你有几台机器、几个人,让人类测试官自己判断就好了。我觉得这是图灵测试后面可以再改进的地方。
深度学习技术在棋类游戏中发展
那么为什么第四版教科书的封面上出现了围棋?1997年深蓝赢了卡斯帕罗夫之后,《纽约时报》想找一位做AI的专家,来评论一下这个成果怎么样。我的导师德鲁·麦狄蒙(Drew McDermott)当时是耶鲁大学计算机系主任,他告诉《纽约时报》的第一句话就是,这个东西不是AI。因为深蓝下国际象棋,基本上就是通过并行计算做一个遍历搜索。因为国际象棋才32个位置,只要你算力足够的话,很容易把所有的步子都算一遍,至少IBM那个时候就做到了,机器基本上输不了。
但是用这个办法为什么下不了围棋呢?因为围棋从第一步开始,理论上是361个点,你都可以选。然后第二步、第三步,你可以在360个点、359个点里面选。这样对一个程序来说,宇宙里面所有分子的数量,都不够用来表示所有的可能性,所以没法用遍历搜索的方法下围棋,机器在下围棋方面一直是不行的。直到2016年出现了突破,它不是靠遍历搜索来决定到底应该走哪一步。我们看到围棋的复杂度,如果你把它做成一个树状结构来搜索的话,那棵树太大了,又大又深,你没法全部把它遍历。
所以Deepmind(谷歌旗下的AI公司)当时就用到了卷积神经网络(Convolutional Neural Network),它把国际象棋上每个点的可能的赢率都算一下,如果你走这个地方,你赢的可能性有多大,这叫估值网络(Value Network)。围棋盘上有360个空的点,你还是能算出来哪个点赢的可能性最大,但是你选的这个点赢率最大,并不等于这个点是最后走下来最合适的点。所以它有另外一个网络,叫策略网络(Policy Network),就是我一步一步走,它也可以算三十几步,就跟国际象棋的三十几步差不多,基本上就用三十几步的路径来算一下哪个路径最合适。这两个网络都是神经网络(Neural Network),把两个网络算的内容加在一起,一个是棋盘上某一个单独的点的最大赢率,另外一个是走十几步、二十几步或者三十几步,哪一条路径最好。在人类的围棋九段高手的脑袋里面,是可以看十几步的,但是三十几步,他们看不到。所以后来机器就完全比人类强了,这是当时的一个突破。
但是它有个特点,2016年的AlphaGo(Deepmind研发的AI程序)是用人类高手的100万盘棋谱训练出来的,所以它就通过100万盘棋谱计算,大家下围棋时一般走哪一步,这个概率可以算出来。为什么李世石还赢了AlphaGo一盘棋?李世石当时输掉了前两盘棋,已经没有心理负担了。在下第三盘棋的时候,他走了一个不常见的走法。AlphaGo根据高手的传统走法计算怎么下棋,碰到李世石的这个走法,它就蒙了,不知道应该怎么应对,所以说李世石还赢了一盘棋。
AlphaGo登上了《自然》(Nature)杂志封面,但是在我看来这并不是最大的成功,最大的成功反而是Deepmind后面一年的工作,就是研发出了AlphaGo Zero。AlphaGo Zero不用人类下过的棋谱做训练,它就设计两个最简单的、只知道规则的机器棋手——Alpha和Beta。围棋规则很简单,所以很容易在计算机里面把它们的规则定好。机器棋手是不用休息的,让它们24小时不停地互相下,这两个机器棋手就能不断地提高水平。到AlphaGo Zero出来以后,它的胜率大概是AlphaGo最初版本的100倍。所以在李世石跟AlphaGo下围棋的时候,人类还有可能赢。到了AlphaGo Zero这样的技术水平,它跟当时世界围棋排名第一的柯洁下时,柯洁就一点机会都没有了。

2018年图灵奖得主
一般来说,图灵奖不像菲尔兹奖,要求40岁以下的人选才能获奖。图灵奖和诺贝尔奖基本上是一种终身成就奖。所以图灵奖一般会在研究者做出研究成果的很多年之后授予,作为对他的成就的承认。但是深度学习出来以后,特别是AlphaGo、AlphaGo Zero出来以后,图灵奖很快就授予了三巨头——约书亚·本吉奥(Yoshua Bengio)、杰弗里·辛顿(Geoffrey Hinton)和雅恩·乐昆(Yann LeCun)。人们有一个误区,认为这三个人是AI之父,这绝对是错误的,说他们是深度学习之父是对的,深度学习只是AI比较新的或者比较成功的分支。
其实,围棋是比较小众的棋类游戏,特别是在西方世界。一般来说,就是中国、日本、韩国三个国家的人比较喜欢下围棋。我觉得后面的这项工作更有意义,2020年AlphaFold2(Deepmind研发的AI程序)出来了,上个星期AlphaFold3出来了。它们基本上可以开展对原来技术水平来说很复杂的科学工作,比如蛋白质结构预测。因为一个氨基酸的序列,你可以折叠成各种各样的蛋白结构,AlphaFold可以算出来哪几个结构的可能性更大。当然它也不能根据一个序列(sequence)推断出,一定就是这样一个结构,它给出的是概率,但是它的预测准确度当时已经超过80%了。对人类来说,工作就变得很简单,你可以先用机器帮你算一下,然后针对比较可能的那几个结构,再去做湿实验,这大大节省了时间和财力、物力。
另外,从机器人的角度来说,波士顿动力应该是全球做得最好的,因为AI的发展必然会带动机器人的进步。现在假如你把大模型或者深度学习的东西,加到机器人里面,它的整个动作都会比原来的更精确。
大数据的4个特征
大数据是在大模型之前比较火的一个概念。大家可能都理解,因为特别是在我们这个时代,经历了互联网、iPhone,应该说数据的产生和处理比原来多得多。
大数据基本上有3个特征,叫做3个V。一个是规模性(volume),就是数据量非常大。从数据的增长速度来看,大模型的参数都是这样的,不是线性的增长,而是指数级的增长。另一个是速度性(Velocity),处理数据时要快速地解决。我举个例子,你如果要尽快地完成促销,捕捉到用户的信息后,要赶快行动起来,不然用户的兴趣会发生变化。你要是隔上一星期、两星期,才知道用户对这个东西感兴趣,这时用户可能已经不感兴趣了。像医疗健康这类行业,你发现一些异常,要赶快处理。还有一个是多样性(Variety),一定要把不同种类的数据放在一起处理,这样才有意义,才能更好地做决定。数据种类是各种各样的,不仅有文本、序列,还有图片、表格,它们都在一起,这也就是所谓的多模态,跟大模型其实也相关。
原来大数据的特征肯定是这3个V,现在我对第四个V——真实性(Veracity)特别感兴趣。特别是在大模型出现以后,数据越来越不可信了。所以数据的准确度、一致性、真实性都成了问题。在这种情况下再说大数据,一定要强调真实性。
大模型的参数规模呈指数级增长
接下来我介绍大模型时代。大家都知道,特别是在2022年底,大模型的关注度增长非常快。因为你用搜索引擎的时候,可以看出一个词的关注度。另外一点,ChatGPT(OpenAI研发的聊天机器人程序)的用户数5天达到100万,更夸张的是,不到两个月,它的用户数达到1亿。所以它是历史上用户数最快到达1亿的App。我可以说这肯定是前无古人的,但绝对不是后无来者,我相信下一个爆款App的用户数应该会比ChatGPT更快地达到1亿。因为ChatGPT出现以后,大家对AI的接受速度快了很多,我相信下一个爆款App出来了,更多人会很快地去用。
我刚才给大家做了一点科普,AI这个词在1956年就有了,后来出现专家系统(Expert Systems)等词。如果从参数这个角度来说,专家系统的参数基本是零或者比较少。深度学习的参数就比较多了。到了大模型最初的产品GPT-1,它的参数大概是1000万。到了GPT-3,它的参数达到1750亿,模型参数(Model Parameters)的增长曲线在这里出现了拐点。GPT-4的参数大概是1.8万亿,不到10万亿。而且模型参数的增长跟大数据一样,它绝对不是线性增长,而是指数级的增长。
模型参数不是指有多少个神经元,而是指有多少个神经元之间的连接。因为一个神经元可以连很多个神经元,所以它自然对应着多个连接。今年年底就要出来的GPT-5,它的参数至少是5万亿至10万亿。人脑中大概有100万亿个连接。其实人脑的神经元数量大概也就是100亿个,但是假如人脑中的连接,是任何一个神经元连接任何一个神经元,那么连接的数量就是100亿个乘以100亿个,这个数量太大了,所以人脑中的神经元只是和附近的一些神经元连接,而不是和所有的连接。
从这个角度来说,我觉得大模型发展到了GPT-5,成为10万亿参数的模型,它的能力基本上跟人脑差不多了。人脑虽然有100万亿个连接,但是人类平常使用的面积大概只有十分之一,人脑很多时候都是闲的。当然阿尔伯特·爱因斯坦(Albert Einstein)大脑的使用面积可能大一点,普通人使用不了那么多。所以根据我的估计,这条路如果走通了,这是一个模拟人或者逼近人的智力的最佳方式。10万亿参数的模型就足够了,我们就拭目以待吧。因为山姆·奥特曼(Sam Altman)已经在不同场合放话了,GPT-5会比GPT-4强太多。
Transformer算法推动生成式AI发展
生成式AI不仅是最早的文本对话机器人,其实在图片、视频领域,现在也能看出来它有一个非常清楚的多模态联系。为什么它能把这些模态的联系建立起来?它用的算法,不仅只是文本之间相互的token(文本中的最小语义单元)的联系,还可以把文本和图像、文本和视频、文本和声音都联系起来。2017年,其实就出现了现在大家都在谈的生成式AI这个概念,但是2022年的ChatGPT真正让大家认识到大模型、生成式AI有这么强大的功能。
其实OpenAI选了一个大家都不看好的方向来突破。人们从2018年10月开始做大模型,一直没有找到突破点,让大家知道这个东西有用。结果OpenAI选择做了对话机器人(Chatbot),其实这个东西最早从20世纪50年代—60年代就开始做了。只要做AI,你就会想到去跟它对话,做智能客服什么的,但是原来做得都不太好。到了2017年,谷歌发明了一种叫Transformer的算法。我认为发表关于Transformer论文的这些人里面,未来肯定有人拿图灵奖,关键是这篇文章的作者名单很长,到底把奖给谁是个问题。因为图灵奖最多就给三个人,所以怎么把这几个人挑出来,我觉得是评委会发愁的问题。
我讲讲Transformer的原理,我可以用它算我输入的所有token之间的关系。我经常举这样一个例子,姚明有没有拿过奥运奖牌?姚明没有拿过。如果我现在问GPT-3.5这个问题,它的回答还是错的,GPT-4和文心一言的回答是对的。GPT-3.5一直认为姚明拿过奥运奖牌,这是因为我们在做模型预训练的时候,其实是在做完形填空。比如我把姚明、奥运等几个词列出来,把中间的奖牌这个词给抠掉,让大模型去猜,姚明到底有没有拿过。GPT-3.5在做这个完形填空的时候,就去把姚明、篮球这些词,跟奥运会的金牌、银牌、铜牌联系起来,相当于它算了一个概率。它用大量的语料去训练,就能够把这些词的关系给算出来。当时我对GPT-3.5的回答也好奇,就去网络上搜索姚明、奥运、奖牌这些词,没有任何一个网络上的公开信息说,姚明拿过奥运奖牌。
那么GPT-3.5为什么这样回答?当它接收你的问题的时候,它先算一下哪些词跟姚明、奥运、奖牌这几个词相关。跟姚明相关的词,是篮球、NBA、选秀状元、世界第一中锋、国家队主力。跟奥运相关的词,与姚明联系在一起的是悉尼、雅典、北京三届奥运会。跟奖牌相关的词,那就是金、银、铜三种奥运奖牌。所以这是第一轮,在它算了相关性以后,就把这些词给找出来了。再想想这些词之外的词,就不一定跟姚明相关了。比如它看到伟大的篮球运动员、MBA选秀状元、第一中锋这些词,就会想到科比·布莱恩特(Kobe Bryant)、勒布朗·詹姆斯(LeBron James)、保罗·加索尔(Pau Gasol)。GPT-3.5想到这几个人的话,再去联想他们参加的奥运会、他们是否拿过奥运奖牌。他们拿过奥运奖牌的。所以,它从合理性角度计算,姚明那么伟大,伟大到和这几个人相提并论,姚明就应该拿过奥运奖牌。所以GPT-3.5的问题就出在这里。但是GPT-4或者文心一言就不会出现这种情况。这种问题是问事实、历史的问题,不是让它来写一首诗、一部小说,它不需要生成内容。它直接去搜,一搜的话就会发现,姚明确实没有拿过奥运奖牌。
Transformer产生了预训练语言模型。语言预训练能够把关联关系建立起来,可以完成完形填空。但是如果你要用它真正来做一些事,要用新的强化学习算法RLHF(Reinforcement Learning with Human Feedback,即从人类反馈中强化学习),用人类的反馈指导模型做具体的工作。因为预训练只是把一些基础的知识、基本的概念给建立起来了,但它应该做什么事,由你来告诉它。所以GPT-3.5这个模型,是基于GPT-3来训练它的对话的,给它一些对话的标准答案,看它答得怎么样。它答得好,我给高分,答得差,我给低分。要不停地给它一些反馈,不断地提高它。
生成式AI的几个特征
生成式AI的技术突破有4点原因。第一是模型规模,GPT-3的参数规模是1750亿,GPT-4的参数规模是1.8万亿。清华的开源模型ChatGLM,参数规模也能达到1300亿。现在看来,基本上参数规模在千亿以上的模型,性能是比较突出的。第二是训练数据,因为做完形填空,是不需要做标注的。我们把所有数据扔进去,万亿的token也好,各种类型的数据语料也好,扔进去让它不停地去填空。这是一个好处,它不需要人来做标注。第三是训练方法,可以把人类的反馈加进来。第四是算力,英伟达A100显卡和高性能并行计算平台,提供了超强算力支持。其实英伟达这个公司一开始不温不火,它就是做电脑游戏需要用到的显卡。后来,人们发现它的显卡可以给深度学习模型用。特别是到了大模型时代,更是需要它的显卡。所以英伟达是现在最火的公司,它的市值涨上去了。黄仁勋也成了美国工程院院士,他也在做建议,要引导AI的发展方向。生成式AI成就了黄仁勋。
从生成式AI的整个架构来看,在硬件设施也就是算力层面,英伟达的市场份额可能占了95%,其他厂商包括谷歌、英特尔、华为、百度昆仑芯等,最近好像AMD也准备做AI芯片。硬件设施层面之上是云平台,因为这些算力最后要放在云上面来计算。云平台层面之上是模型,模型又分为闭源模型和开源模型。模型层面之上是应用,千万不要认为ChatGPT或者文心一言是大模型,它们是基于大模型的应用。另外,也有一些做生态的公司,做端到端的解决方案。
我再讲讲生成式AI的应用场景。生成式AI现在已经能够生成对话的文本,也可以写代码,生成图像和视频。可以确定的是,GPT-5是一个多模态的模型,多模态已经不是什么新鲜事了,但GPT-5可能是多模态里面做得最好的。因为OpenAI已经提前把Sora(OpenAI研发的文生视频大模型)给放出来了,大家一下子就惊呆了。包括我也惊呆了,我不认为那么早能做出这么好的文生视频,结果它今年初就做出来了,非常惊人,所以我们跟他们是有代差的。从行业应用来说,生成式AI可以用来开发小程序,节省效率,也可以应用于消费品、制药、金融、娱乐、保险等行业。从应用场景来说,它可能涉及营销、销售、物流、客户支持、法务、财务、人力资源等多个方面。在任何行业、任何企业的不同职能部门里面,我们都可以用到生成式AI。
提问环节:
问:您刚才讲到,属于前大模型时代的早期AI技术,现在还有一些应用,比如说大模型的成本比较高,现在有些地方没法部署。这部分传统的AI技术在大模型时代还能存在吗?还是说目前应用这些技术的场景,以后都需要慢慢转型,去使用大模型?
窦德景:我在咨询公司时也经常听到类似的问题,值不值得花成本去训练大模型?我想对大多数企业来说,应该不需要自己训练模型。比如千亿参数的模型,大概需要至少几百张显卡甚至上千张显卡,训练几个月,才能训练出来,算力和时间成本很高。你就算不训练上亿参数模型的话,你使用模型,也需要投入几百万元。
总结一下,如果一定要追求大模型的效果,你的投入可能暂时也低不到哪去。我们一般会给用户算投资回报率(ROI),你投入了多少,最后产出了多少。我当时参与过一个医药公司使用大模型培训医药代表的项目,他如果每年都推出新药,这笔账肯定是划算的。但如果几年就培训这么一次的话,真不见得要使用大模型。
问:传统的AI技术供应商要么去做大模型的微调,保持自己服务客户的能力,要么就会被市场淘汰了?
窦德景:传统供应商不能寄希望于一些出不起钱的公司,来继续做他们的客户,他一定要有这个能力。但有一点好处是,大模型其实还是比较好用的。如果他原来就是搞AI的公司,要转型去做生成式AI,就是换块牌子,这个能力其实还是很容易掌握的。训练或者微调、提示、加训,我觉得都能做。我这一年多也接触了一些小公司,他们转型还是很快的。
问:想请您预判一下,GPT-5出来之后,会对现在的AI能力有多大程度的提升?现在的大模型有各种幻觉,有人觉得不好用,GPT-5会变得好用吗?
窦德景:GPT-5的幻觉会减少,因为GPT-4的幻觉已经比GPT-3.5减少了,我前面说的姚明的例子就很明显。但它绝对不是100%的准确,这是第一点。第二点,GPT-5肯定是多模态。第三点,既然Sora现在放出的视频都大概有一分钟,GPT-5生成的视频肯定会更长、更逼真。现在Sora画的几个样本里面,可能挑选出的是比较好的,但是里面还有一些瑕疵,你可以找出它们不符合所谓的物理世界的地方。GPT-5真正出来以后,Sora视频中出现的人的左右腿在行走中互换的问题,肯定会被解决。
问:想问下您个人选择的问题,现在很多做AI的人都在国外,因为跟国外比,国内技术代差蛮大的,您为什么坚持在国内做?另外,您为什么选择去北电数智这样一家算力公司,是看到什么机会吗?
窦德景:第一个问题其实比较简单。我2019年回国时,想的是不一定会留在中国。因为当时美国大学每六年有一个学术休假,在学术休假的时候,我应该去哪都可以。我当时计划在百度待个半年一年就回学校了,结果因为家庭等各方面的原因,就待下来了。到这一次再选择的时候,其实我今年3月去美国出差,还回了趟学校。他们肯定还是欢迎我回去的,但是如果我现在去美国的话,我在国内三四年时间积累的一些合作伙伴和关系,基本上用不了。所以我的选择更多还是基于现实考量。
第二个问题,北电数智有算力,我们可以用这些算力服务国内的模型公司。他大概会有1000P—2000P(P指10的15次方)的算力。用英伟达的显卡来比较,一张A100的显卡,算力大概是零点一几P,一台有8张显卡的服务器,大概是1P。所以1000P的算力是很大的,相当于8000张A100显卡。
而且我们做的另外一件事情,是把国内的芯片拿来做适配,因为很明显现在国内已经买不到英伟达的显卡了。所以我们一定要想办法,帮助国内还能用的芯片被使用起来。这些芯片来自华为、百度昆仑芯、摩尔线程、寒武纪等公司,我们拿它们和英伟达芯片一起工作。
以后我在复旦大学里面花的精力会更多一点,做比较前沿的研究。在大数据时代,我其实还不是最看重第四个V(Veracity)。大模型出来以后,数据的准确性、真实性是很大的一个问题,现在的大模型在我看来是不安全的。第一点,大模型产生的一些信息,你要是完全不考虑真实性的话,会出问题。第二点,我觉得大模型本身并不坏,大模型不会自己主动地想去作恶,但总会有些坏人想利用大模型作恶。就像人类最早研究质能方程,是希望用核能的办法来产生更多的能量,产生核电。但是核武器出来以后,一旦恐怖分子拿到核武器,会是很大的一个问题。同样,我觉得大模型以后的发展需要监管,需要安全的控制措施。所以在回到学校以后,我会更关注大模型安全方面的问题。
问:不考虑伦理的问题,人类能不能造出超强大脑?您预测多长时间可以造出超强大脑?
窦德景:先定义一下超强,我理解你想表达的意思是比人还聪明。应该说,目前大模型技术绝对是在往这个方向走。我觉得没有任何理由说,以人的智力画一条线,限制AI一定不能超过人。而且AI现在在很多方面已经超过人,GPT-5可能也会在很多方面超过人。如果按照这个定义,人类已经造出超强大脑了。
其实伦理方面的问题是什么?我们现在一定要想办法,建立一套从上到下的机制或者是比较民间的机制,来限制AI作恶。我刚才已经提到这个问题,我不认为现在的AI会主动作恶,AI还没有自我意识。如果AI没有自我意识,它不会真的为自己谋霸权、谋利益。人类为什么会自私?人的自我意识是天生的。即使某一个人生下来了,他的基因里面没有自我意识,这种基因也很快就会失传,因为他活不下去的。所以反过来说,现在的AI还没有自我意识,它不可能为自己谋利益、谋霸权,但是怎样防止有些坏人想通过AI来统治其他人或者统治世界,这个是我们要关心的事情。
问:超强大脑以后会有自我意识吗?
窦德景:我现在看不出有办法让它有自我意识。我在几个公众场合都讲过,这是我自己的一个理论,可以说是我首创的。我认为,人为什么会有自我意识,是因为人生活在地球上,或者说我们这些碳基生物生活在地球上,资源是有限的,如果你不去争资源,你就活不下去,所以你天生就会有自我意识。或者说一开始有些人类、猿人是没有自我意识的,有些有自我意识,结果没有自我意识的在过程中就被自然淘汰了。毕竟,碳基生物生活在一个资源有限的世界。
对硅基生物来说——假如我们认为大模型已经具备了生命或者生物的一个基本形态的话,至少我们没有看到电能已经少到让一些机器人活着、另外的一些机器人就要死掉的状态。但是,地球的资源还是有限制的。地球可能可以承载100亿人,如果地球上的生物全变成硅基生物,地球肯定能承载200亿个、300亿个。假如地球上有1000亿个硅基生命,我觉得不管水电、风电、火电可能都不够用了,那时候硅基生命就会打起来,就必须有自我意识了。
问:其实大模型出来的时候,有很多细分领域也在蹭这个热点。比如在医药领域,当时就有一些制药公司说自己在做AI制药,但也有观点说其实他们用的技术不能叫大模型。我想知道这种垂直细分领域的模型,和大模型到底有什么不一样?
窦德景:很简单,就看它有没有用大模型。因为就算你用最小的大模型,比如清华的开源模型或者Llama开源模型(美国科技公司Meta研发的大模型),模型参数至少是60亿到70亿。理论上,英文单词里面只有大语言模型(Large Language Model),没有大模型。大模型这个概念,在英语单词里面对应的是基础模型(Foundation Model)。但是我们还观察到,如果模型参数小于几十亿,它的性能也不明显。
特别是医药行业的公司,它不是简单使用大模型的。因为现在这种公开的、要训练的基础模型,它们拿到的这些跟医药相关的信息,都是从网络上公开抓取的,相对来说都不专业。这些信息对特定的医药应用基本上没有用,你必须用你自己的专业数据来做微调或者二次训练,这个成本就上去了。所以,你就看他是不是真正用自己的数据训练,他不把这个过程走完的话,不应该说自己用的是大模型。
问:之前几波AI浪潮,都是经历了高潮,又退潮了。这一波浪潮会是怎么样的?因为从2022年底OpenAI推出ChatGPT开始到现在,好像始终没有找到一个明星级的应用,能够给人类的物理社会带来巨大改变。我看到现在有经济学家说,它可能对全要素生产率没有显著提升。从您的观察来看,这会是一个可能的情况吗?如果始终找不到明星级的应用,它会不会退潮?
窦德景:这是可能的,前两波高潮也是这样的。比如第一波,20世纪50年代—60年代,逻辑推理出来了,后来发现逻辑推理只能把一些确定的信息给推理出来。第二波,贝叶斯、专家系统、浅层神经网络都出来了,最终都没有找到杀手级应用程序(Killer App)。
但是这一波浪潮,应该是在三波AI浪潮里面最有可能成功。我妈妈79岁了,虽然她也是重点大学毕业的,但是她以前一直做仪表那块的东西,可以说是AI的“门外汉”。她对我原来做什么都不是很关心的,结果她有一次问我,你知不知道ChatGPT?她都知道ChatGPT了,你说影响力有多大?这波AI浪潮造成的冲击力,已经扩散到了计算机行业之外,它至少可以跟互联网、iPhone相提并论,在我看来这波浪潮基本上是成功了。
只不过问题是,哪一个App可以先盈利?因为大模型成本比较高,能不能赚到钱,其实是一个ROI的问题。但总会有一个特定的应用出现,因为开源模型本身就不收费,闭源模型也会越来越便宜,我觉得最后闭源模型都可以免费给你用,通过这种手段来拉客户,就像当年的互联网一样。现在基本上大模型公司都在烧投资人的钱,有点跑马圈地的感觉。但是总会剩下几家拥有几亿用户的公司,那他们总是能想办法赚到钱的。
( 史额黎 整理)
 京公网安备 11010802028547号
京公网安备 11010802028547号
 购物车
购物车






