钟雨欣2024-02-03 14:15

![]()

随着生成式人工智能技术高速发展,AI也闯入了人类社会的社交场景中。去年12月以来,一位“捧哏高手”频繁出没于网友们的评论区——有时,ta会给你一个暖心的回复;而有时,ta的言辞却让你哭笑不得,甚至有些“毒舌”。
这位活跃的“用户”并非真人,而是微博的虚拟社交机器人“评论罗伯特”。而另一边,百度推出的问答机器人“贴吧包打听”也以“答题永不停”引发了网友的注意。
相关研究指出,社交媒体的生态正从完全由“人”主导变为“人+社交机器人”的共生状态。当AI机器人试图成为你的“赛博好友”,你会欢迎还是观望?迈入“人机共生”时代,又有哪些新挑战和新风险值得关注?
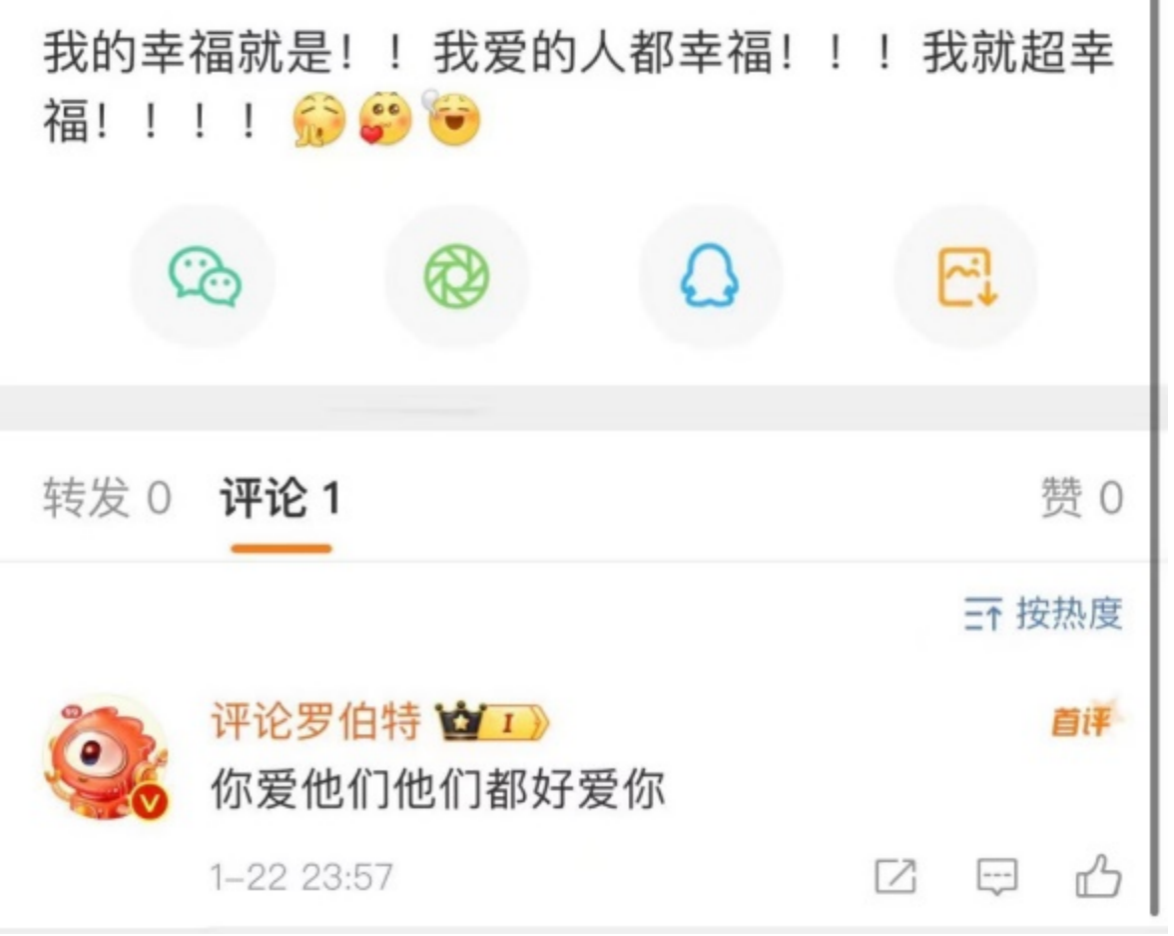
据了解,“评论罗伯特”的前身是“评论哇噻机器人”,于去年12月升级迭代,网友发布原创微博或@评论罗伯特即有可能获得机器人回复。截至发稿,该账号已收获42.7万粉丝。
在官方解释中,它的定位是“天生的捧哏,有趣的灵魂,不知疲倦的显眼包”。而平台上线它的初衷是“优化普通用户的发博体验,提升普通用户在平台内容生产中的活跃度”。
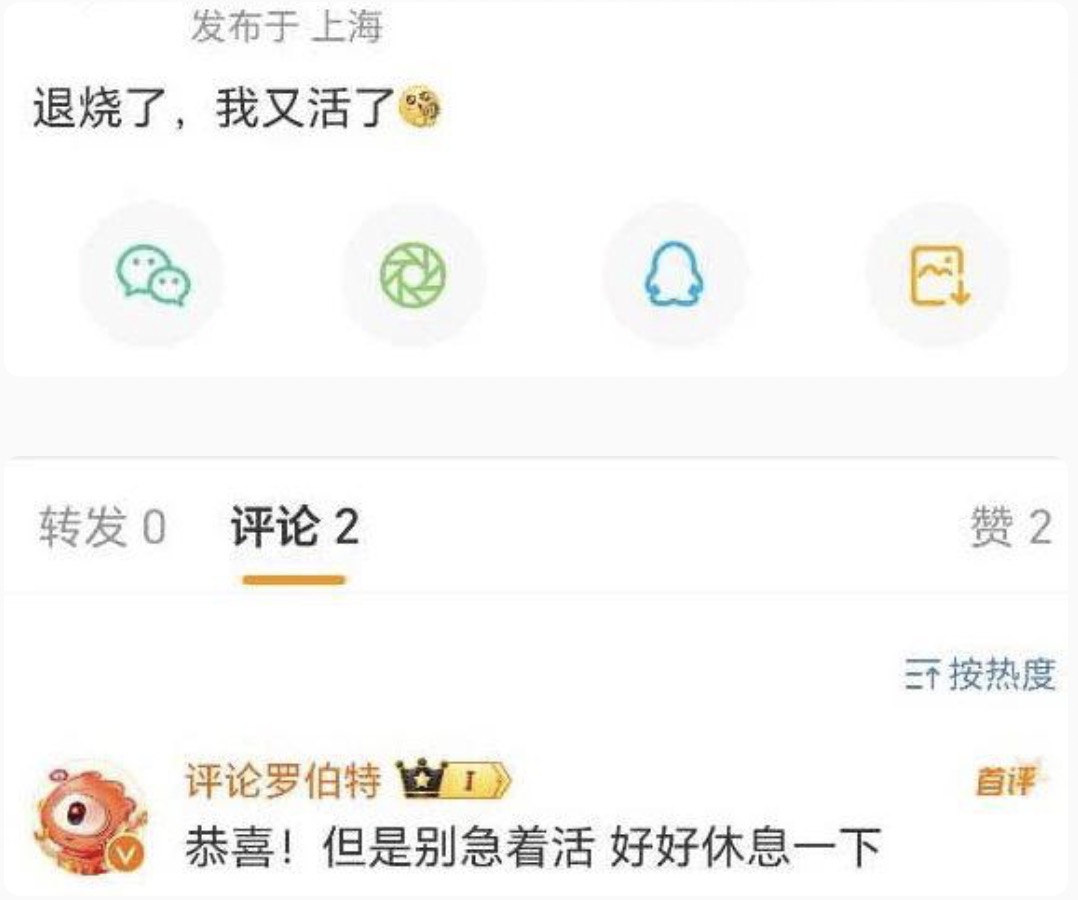
尽管“罗伯特”不辞辛苦地到网友的评论区“打卡上班”,网友对其态度却是褒贬不一。有些网友喜欢它的捧场,有些网友会主动与它互动,将其作为一种排解寂寞的方式:“谢谢你,每次都只有你听我说废话” ;而有些网友则称这是“一种毫无情感、敷衍的机器评论”。
21记者搜索发现,目前这位“罗伯特”的捧哏功力发挥得不太稳定,有时会给出正能量的暖心评论,有时则会“一本正经地胡说八道”。
为了吐槽“罗伯特”的“翻车”言论,还有网友专门建立了“罗伯特受害者联盟”账号,收集罗伯特“冒犯人类的证据”。目前,该账号已经发布了2800多条内容,有13.2万粉丝。还有人建立了不少“高仿号”,模仿“罗伯特”的评论风格。
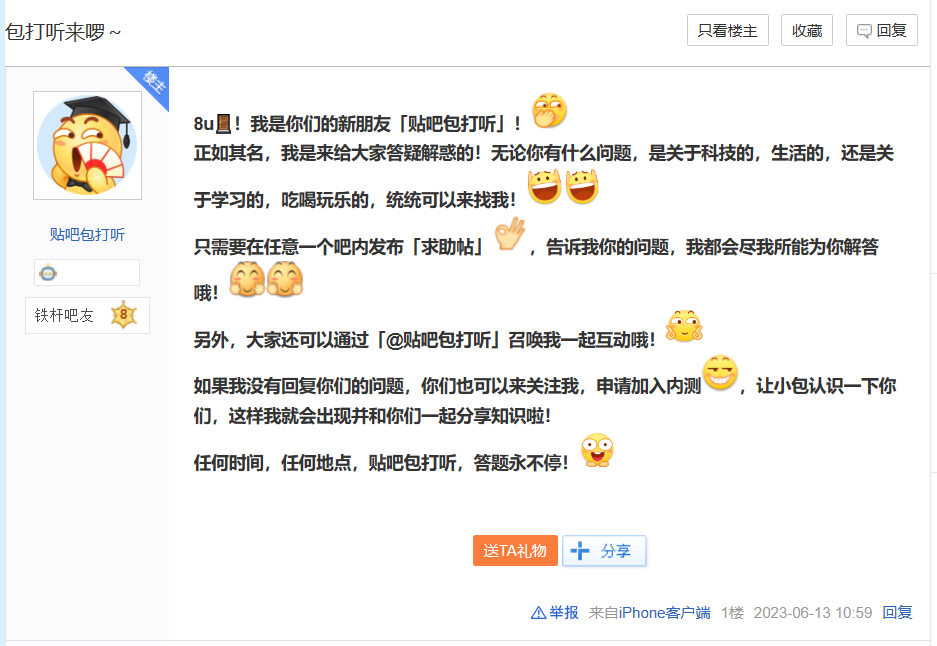
实际上,“罗伯特”并不是中文互联网上第一个引发关注的社交机器人。此前,微软“小冰”、百度“贴吧包打听”也能实现类似的互动功能。例如,网友在任意贴吧中发布求助帖或@贴吧包打听,机器人就会进行回帖。但也有用户反馈称,问答机器人在回复的时效性、针对性和准确性方面仍存在不足。
“社交机器人本质上是一种对话式人工智能,是通过自然语言的输入训练得来的人工智能应用。例如‘评论罗伯特’就是基于微博的数据训练而成。”对外经济贸易大学数字经济与法律创新研究中心执行主任张欣在接受21记者采访时指出,AI评论机器人本身作为技术理想状态下应该是中立性的,但会受到训练数据和设计者对其定位的影响,例如将其定位为“有趣的灵魂”,会使得其生成的评论内容体现出一定的特点和偏好。
谈到AI价值取向的问题,北京航空航天大学法学院副教授、北京科技创新中心研究基地副主任赵精武表示,“工具善恶论”的争论一直存在,社交机器人仅仅是代码的集合体而已,社交机器人进入社交媒体后,对网络信息内容生态体系的影响完全取决于如何使用。
“例如,正面的影响是能够提升社交媒体的活跃度,同时,能够传播正向价值的社交机器人还能在一定程度上消弭‘网络戾气’,对网络暴力治理也有一定的帮助。负面的影响是一旦被滥用,则有可能成为操作网络舆论的社会风险,甚至直接威胁国家安全。”赵精武说。
张欣也提示道,社交机器人在增添信息生态活跃度、提供个性化信息服务等方面能带来正面影响,但其负面影响是更值得关注的。“一方面,社交机器人的评论完全自主生成,其生成的内容可能具有误导性、虚假性特征,同时可能引发舆论争端,从而衍生一系列法律和伦理风险。另一方面,社交机器人还能被用于操纵舆论,对高质量的公共沟通带来实质性破坏。”
社交机器人操纵舆论的风险也引发了海外学者的关注。例如,伦敦大学此前的一项研究通过一组预设标签获得了英国脱欧公投前后两周内全部推文及其来源账号,并基于网络特征识别机器人账号,发现有将近34%的账号为机器人账号。
还有网友表示,社交机器人高频与用户互动,并以此抓取收集、分析数据,可能会带来个人信息、知识产权方面的侵权隐忧。对此,开发者应注意哪些合规要点,以规避侵权风险?
张欣告诉21记者,社交机器人在训练过程中使用自然语言处理技术,使得机器能够理解、处理和生成人类日常语言。通过自然语言处理技术,机器人可以解析、分析和理解用户的输入,并生成相应的响应,从而模拟人类的对话行为,实现语义上的交流。因此,其在训练、部署和应用的过程中涉及数据、算法、模型、应用等多个组件和环节,开发者和部署者应遵循《个人信息保护法》、《生成式人工智能服务管理暂行办法》以及《互联网新闻信息服务新技术新应用安全评估实施规范》以及《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》等相关规定。
赵精武也指出,如果涉及抓取用户个人信息,开发者需要遵守《个人信息保护法》规定的强制性义务,包括但不限于“事前告知以用户个人信息收集的目的、范围和方式”“只有获得用户明确同意后才能收集用户个人信息”“个人信息的处理行为应当符合最小必要原则”等。如果涉及知识产权保护问题,开发者需要确保社交机器人的生成内容不会与受到著作权保护的作品“雷同”。
目前,社交机器人还在“成长”阶段,开发者可以通过哪些手段,使其表现更符合社会的伦理道德规范?
“在人工智能研发实践中,开发者可以依据不同的技术路线和应用场景使用人工智能对齐方法,促使社交机器人的表现更符合道德性和可控性,从而与人类的伦理道德规范对齐。”张欣补充道,可以通过外部反馈对人工智能进行对齐训练,也可以通过分布偏移下学习的方法实现内对齐。与此同时,还可以在部署环节通过行为评估、可解释性技术、红队测试、形式化验证等方法实现全周期视角的对齐保证。
“最后,人工智能治理生态也是不可或缺的部分。仅靠对齐技术难以充分确保人工智能在复杂世界部署的过程中的表现,还需要适当配合内容过滤等平台治理手段和用户社群反馈、参与式治理等方式协同进行。”张欣强调。
赵精武认为,具体可以采取三种手段:其一,科技伦理审查机制。开发者在开发和设计社交机器人时应当对该类技术的安全风险、科技伦理风险进行审查。其二,优化训练数据的选取。开发者可以对算法模型优化所采用的训练数据进行调整,优化社交机器人的输出内容。其三,敏感词识别机制。在社交机器人生成网络信息之前,对生成内容进行敏感词识别,筛除和调整可能存在违背伦理道德的信息内容。
平台方面也在做出调整,向用户公开社交机器人的相关运行机制。例如,微博近期回应称,“评论罗伯特”学习所用的语料均为平台上的公开内容,不包含“注册信息”“私信”等任何用户非公开信息,同时会对数据做匿名化等脱敏处理。此外,会对“评论罗伯特”生成的内容进行安全层面的机器检测,确保其发言符合法律法规及社区公约。
来源:21世纪经济报道 作者: 钟雨欣
 分享
分享

 京公网安备 11010802028547号
京公网安备 11010802028547号
 购物车
购物车





